
Quero primeiramente agradecer ao convite da Sabrina Vasconcellos, é uma honra fazer parte do Universo SAVA.
Durante esse artigo vamos ter uma visão completa de ponta a ponta de Web Scraping, desde sua contextualização até aplicação em People Analytics.
O que é Web Scraping?
Web Scraping não passa de uma extração de dados, no caso essa extração costuma ocorrer de forma automática, e sempre ocorre em algum site ou alguma plataforma da Web.
Dentro dos sites temos uma linguagem chamada HTML, que armazena as informações do site, tanto como conteúdo como parâmetros. O nosso computador é capaz de ler essas linhas de códigos e transformar em conteúdo visual.
O que fazemos pelo Web Scraping é simplesmente voltar um passo, fazer o computador ler e puxar o HTML para conseguirmos extrair alguma informação.
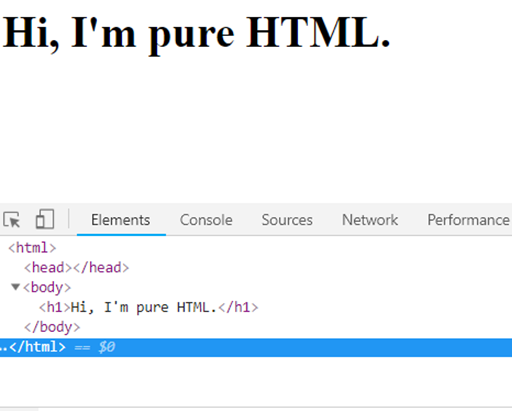
O nosso computador lê as linhas de códigos e transforma isso em conteúdo visual, no caso o “HI, I’m pure HTML”, até porque ninguém merece ter que ler linhas de código para conseguir entender algum conteúdo, o computador simplifica o caminho.
Para conseguirmos extrair o conteúdo acima seria simples, precisamos somente falar para o computador puxar a linha <h1> e quando ele fizer isso teremos a informação “Hi, I’m pure HTML”. O comando para fazer o computador extrair a linha <h1> pode se originar da linguagem Python abaixo comentamos como fazer essa extração de forma muito simples.
Mãos na massa para extração do “Hi, I’m pure HTML”
Com auxílio de bibliotecas do Python fica fácil solicitar ao computador extrair o <h1> . Para essa tarefa utilizamos as bibliotecas: Beautiful Soup – responsável pela extração do conteúdo e Request – responsável por fazer uma requisição na página para puxar informações. O código para extração do “Hi, I’m pure HTML” pode ser observado abaixo:
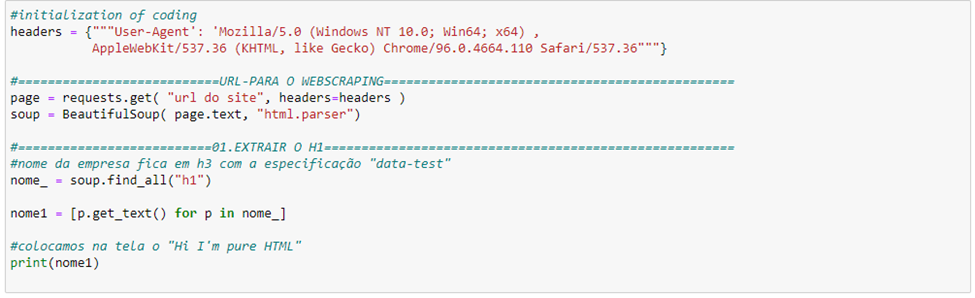
Com os comandos acima conseguimos extrair o conteúdo do HTML. Utilizamos o comando “headers” para fazer a requisição no site, esse código é nativo da biblioteca Request. O poder da extração está no comando “BeautifulSoup” ele quem puxa todo o código HTML para o python, depois só precisamos utilizar o comando “soup.find_all(‘h1’)” para puxar o “<h1>”. Após isso podemos agrupar em uma variável e solicitar para printar na tela com o comando “print()”
Web Scraping na prática e onde pode ser aplicado:
Quando queremos comprar algo temos o costume de comparar o melhor preço em diferentes sites, nós costumamos procurar em um site confiável e o melhor preço. Para nos auxiliar nesta tarefa temos a presença de sites que comparam os preços.
Se um dia quisermos entender ou fazer um site que compara preços: um método possível seria utilizando o Web Scraping. Podemos monitorar os melhores preços de vários sites e atualizar todos os dias de forma automática. Assim o nosso problema de uma compra confiável e com um custo menor seria resolvido.
Universo Web Scraping aplicado a People Analytics:
Claro que no mundo de People Analytics os relatórios costumam surgir na empresa em que trabalhamos. Até porque somente nós temos acesso a quem foi admitido, desligado, qual o índice do turnover e etc… O web scraping pode se tornar um PLUS em people analytics e um diferencial.
03 Exemplos práticos em People Analytics
- 1 – Monitorar novas nomenclaturas e funções de cargos
O nosso atual cenário da Tecnologia evolui muito rápido e com constância, às vezes se torna impossível sabermos os novos cargos e funções do mercado. O web scraping pode facilitar nossas vidas, podemos aplicar um scraping em algum site de busca de emprego e monitorar somente novas nomenclaturas de cargos.

A imagem acima mostra um novo cargo que será tendência no mercado. Podemos monitorar empresas que irão fazer a contratação desse cargo. Como também, conseguimos extrair novos cargos como esse que serão tendência no futuro.
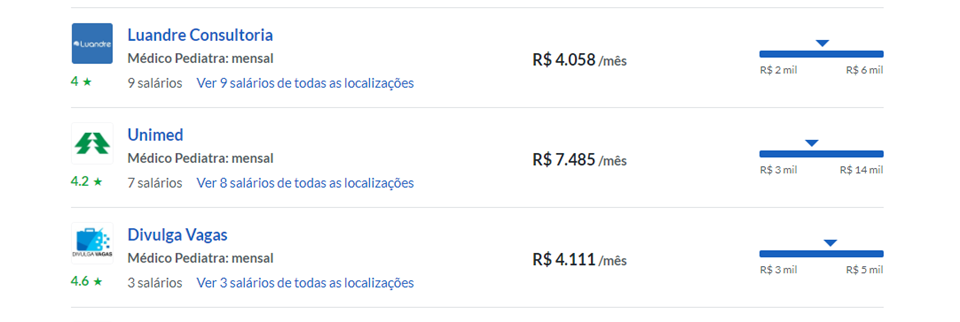
- 2 – Monitorar Salários em função do Cargo.
Só quem já pagou ou participou de algum estudo de tabela salarial sabe quão caro é. Claramente, não está na realidade de todas empresas pagarem um valor alto. O que pode facilitar nesses casos é novamente aplicar um Scraping em sites de busca de empregos para
conseguirmos puxar os valores que as empresas estão pagando para os cargos em questão. (no final deste artigo temos um exemplo feito em python que puxa esses valores). Observação: com esse método conseguimos somente ter um norte de quanto pagar, ainda não temos uma base por posição, exemplo: quanto pagar para SR, para JR, para Especialista…
- 3 – Monitorar as avaliações e a nota da empresa no Glassdoor.
Muitas empresas procuram ter as melhores notas e avaliações no Glassdoor comparado com outras empresas. A medida que isso se torna algo que precisa ser mensurado e analisado em função do tempo. Vale fazermos um scraping para puxar relatórios sobre as avaliações e a nota da empresa em função do tempo.
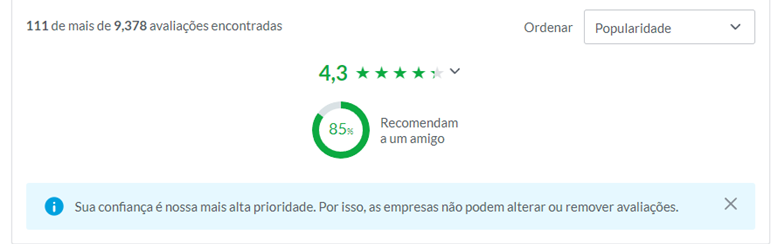
A imagem acima mostra a classificação da empresa “Meta”, podemos monitorar essa classificação por meio de um scraping. Como também, podemos monitorar os comentários de colaboradores e ex-colaboradores sobre a empresa. Com esses dados e informações em mãos podemos tomar decisões orientadas a dados e gerar nossos planos de ações monitorados!
Espero que tenham gostado do conteúdo?! Segue o link do Notebook sobre o exemplo prático 2 – Monitorar Salários em função do Cargo: Clique aqui

Guilherme Sales Grecov
Graduando em Bacharel de Ciência e Tecnologia, experiência em BI e analises de dado. Atua comPeople Analytics na Juntos Somos mais.