
Muitas empresas possuem um fluxo de entrada e saída de funcionários em nível alto. Isso é o que podemos chamar de turnover, um assunto muito quente devido gerar altos custos internos para as companhias.
Imagine que a cada perda de um funcionário (ainda mais se for um talento), a empresa lidará com alguns custos: valores rescisórios, anúncio de vaga, entrevistas, custos de admissão, paralisação ou retardamento de processos, adaptação do novo funcionário, dentre outros mais. Agora imagine isso em larga escala. É o que hoje faz, dentro da área corporativa, tratarem um assunto como turnover importantíssimo.
Neste pequeno projeto, trabalharemos com este tema (em modelo de Case), a fim de sugerir uma análise para resolução do problema da alta rotatividade dos funcionários. A ideia deste artigo é abordar tanto a parte técnica quanto sugerir discussões de negócio.
Para as análises e modelagem, utilizaremos o software R. O modelo escolhido foi o de regressão logística, devido a praticidade e facilidade de entendimento, mas nada nos impede de aplicar outras bibliotecas de machine learning como random forest, XGBoost, dentre outros que possuem melhor capacidade preditiva. No mais, espero que gostem!
Entendimento do Problema
Uma empresa está sendo impactada com a perda de funcionários considerados talentos, em especial aqueles com certo tempo de casa. Existe uma base de dados composta de diversos atributos destes funcionários em relação a empresa, inclusive aqueles que foram desligados. Espera-se descobrir onde e se existe relação entre os atributos observados e o desligamento destes funcionários, além de verificar seus níveis de satisfação juntamente com suas performances.
A base de dados chama-se Turnover conta com 14.999 observações, distribuídas em diversas variáveis como consta na tabela abaixo:

Análise Exploratória
Nesta etapa faremos as primeiras análises a fim de conhecermos e nos ambientarmos à base de dados Turnover. Com isso, serão geradas análises visuais que facilitem o entendimento e direcione nossas interpretações sobre o problema.
Particularmente gosto de usar as funções abaixo para verificar dimensões, estruturas e informações gerais dos dados.
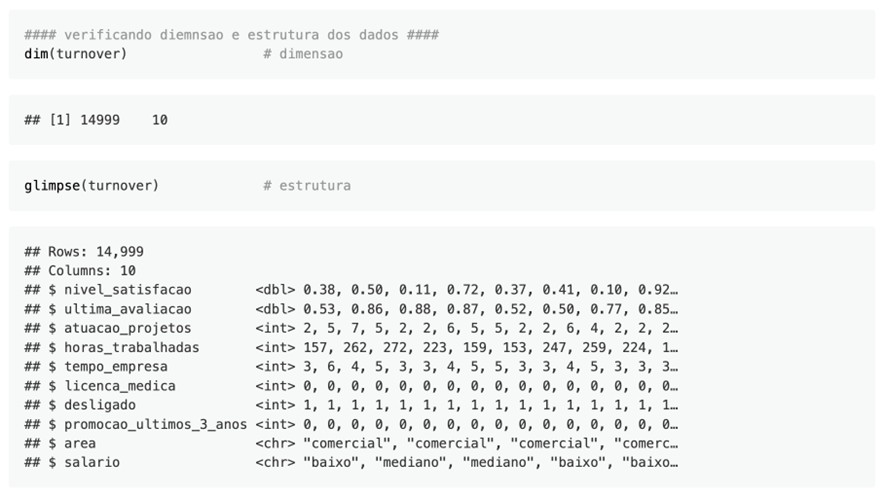
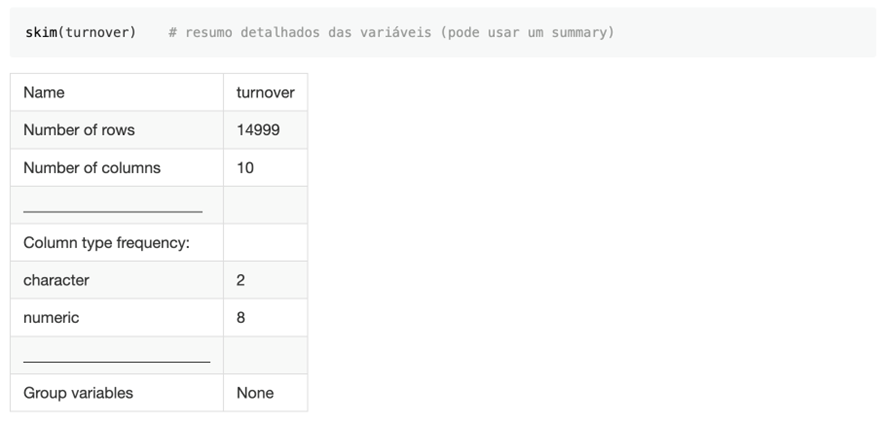

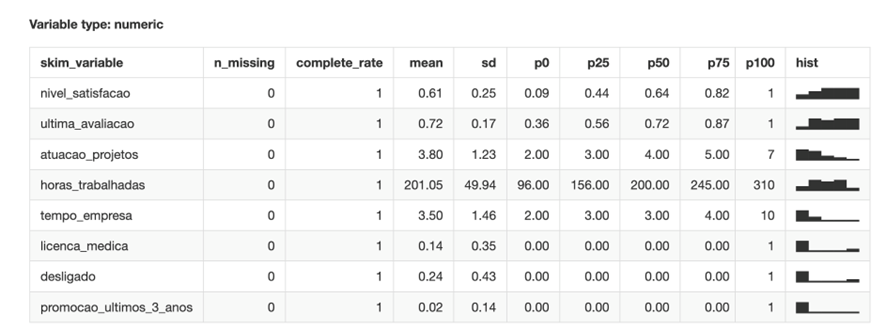
Como pudemos verificar, algumas variáveis precisam de mudança de estrutura para serem mais bem trabalhadas. São os casos das variáveis: desligado, licença médica e promoção, em que transformaremos para fator. Além disso, criarei uma variável chamada Status (do colaborador) para ficarem entendíveis e bonitos meus gráficos! 🙂

Feito isso, utilizaremos o pacote `GGally`, que traz a função `ggpairs`, que faz uma análise de tudo contra todos, o que, muitas vezes, serve para focar em determinados atributos que já demonstram ter algum tipo de informação útil para nossa análise. O gráfico não fica muito bonito, mas acho que o intuito é tentar criar um “chute inicial”.


Com o cruzamento acima, podemos já criar alguns questionamentos sobre a situação dos funcionários desta empresa:
- Quais os pontos relevantes que difenciam os funcionários ativos dos desligados?
- O nível de satisfação é influenciado ou influencia algum outro atributo?
- A avaliação de performance está sendo bem aplicada ou se relaciona a algum atributo?
Inicialmente ficaremos com estes questionamentos, mas durante o processo de análise surgirão novas ideias e perguntas a serem abordadas.
Análise de Performance versus Nível de Satisfação
Uma das boas visualizações para o setor de People Analytics é o gráfico de dispersão cruzando satisfação, performance e desligamento de funcionários. Ele pode, de cara, dizer muito na nossa análise. Vejamos:

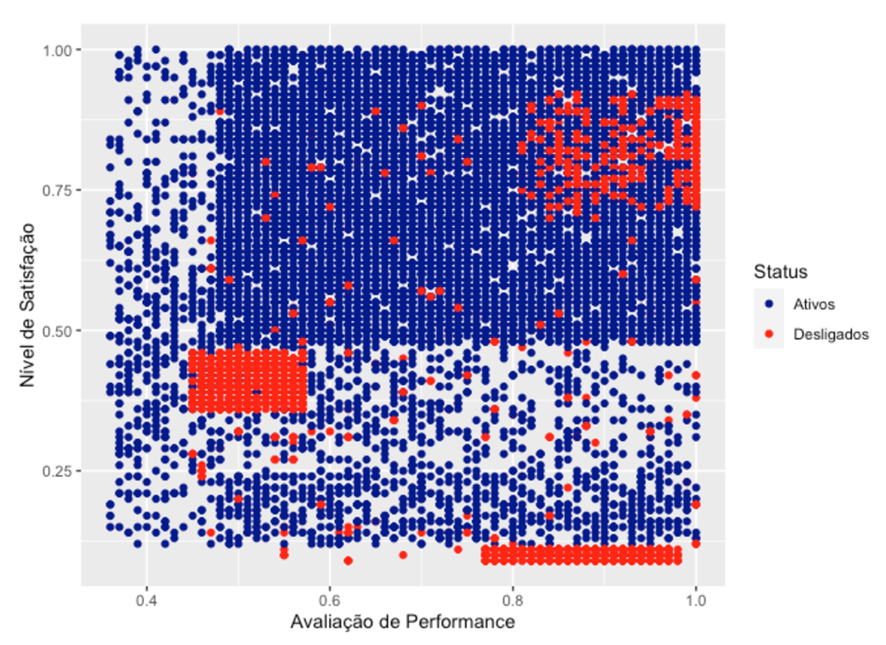
Podemos perceber que as duas variáveis são escalas de 0 a 1. Com isso, pudemos notar que há quatro pontos gerais relevantes neste gráfico de dispersão, por ordem de gravidade da situação:
- Funcionários performando bem (> 0,8) e com bom nível de satisfação (> 0,75) estão com alto número de desligamentos (Satisfeito | Produtivo);
- Funcionários com alta performance (> 0,78/0,8) e com péssimo nível de satisfação (< 0,12) estão com alto número de desligamentos (Insatisfeito | Produtivo);
- Alto número de funcionários entre média e baixa performances (< 0,8) e entre médio e alto níveis de satisfação (> 0.5) em situação ativa (Satisfeito | Improdutivo);
- Concentração de funcionários desligados com baixa performance (< 0,6) e baixo nível de satisfação (< 0,5), o que se mostra mais coerente neste gráfico, porém vamos avaliar melhor (Insatisfeito | Improdutivo).
Sabendo que existem situações bem graves no quadro de funcionários dessa empresa, vamos segmentar e avaliar a base de acordo com os quatro grupos citados acima, para verificar se existem diferenças relevantes:

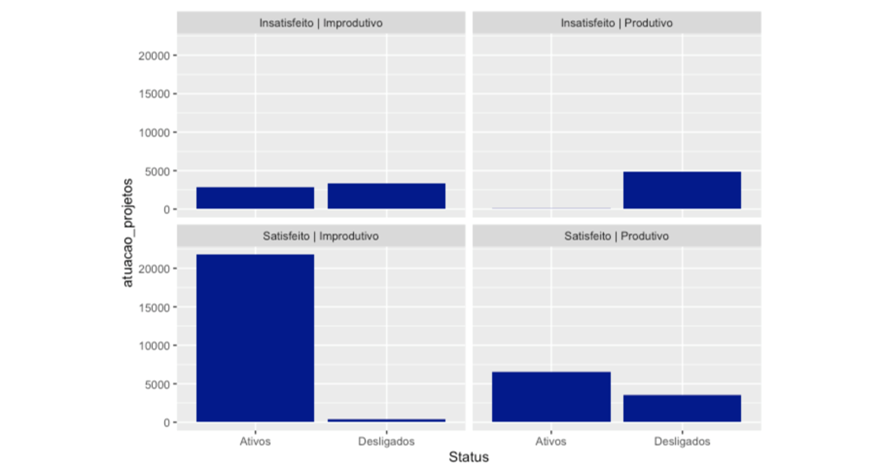

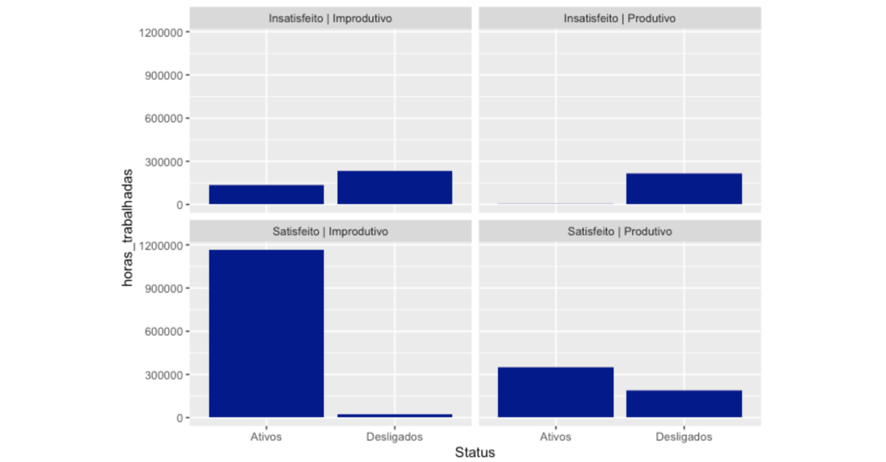

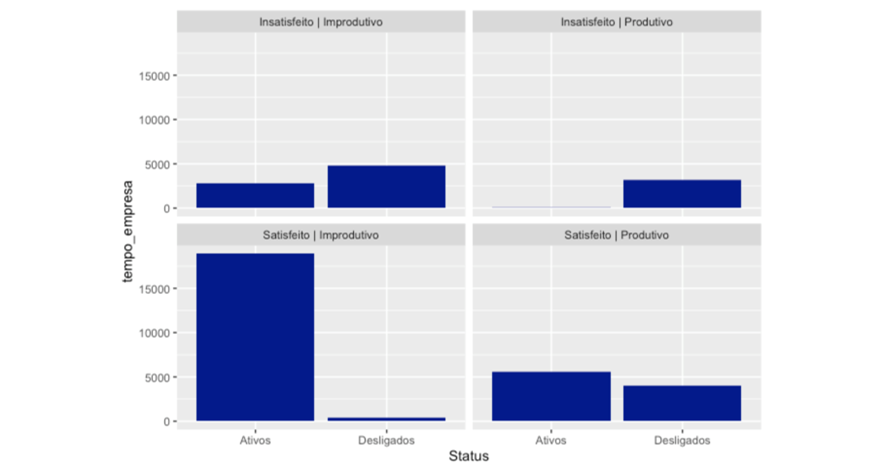
Diante dos gráficos acima, pudemos observar alguns pontos interessantes:
- O maior destaque fica para os funcionários Insatisfeitos | Produtivos e desligados, onde possuem altíssimo número de participações em projetos, com a análise reforçada quando olhamos as horas trabalhadas destes, que possuem mais que os outros grupos: Carga de trabalho elevada?
- Além disso, os funcionários ativos Satisfeitos | Improdutivos têm mais horas trabalhadas quando comparados aos desligados: O tempo destes está sendo bem empregado?
- Quando olhamos o tempo de empresa, o destaque fica para aqueles funcionários Satisfeitos | Improdutivos e desligados, em que possuem bem menos tempo de empresa: Erro de contratação?
Utilização gráficos mais elaborados
Através de gráficos um pouco mais elaborados, vamos aprofundar nossa análise:

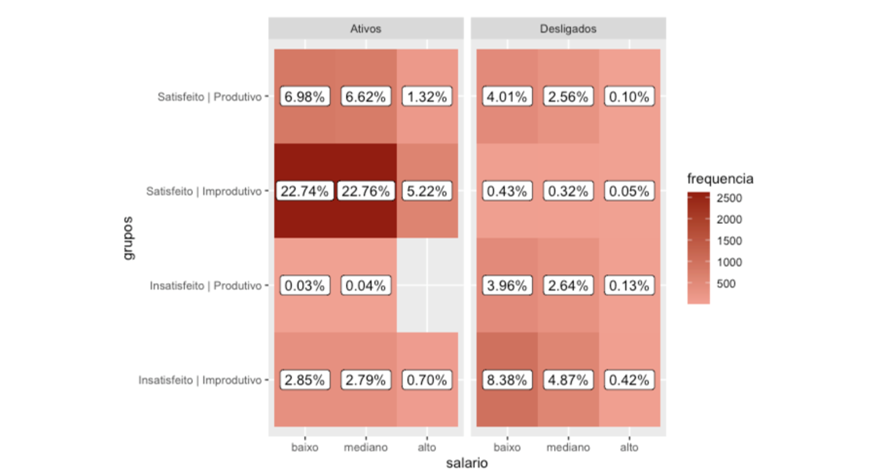
Podemos verificar em relação ao patamar salarial alguns pontos interessantes:
- Patamar salarial alto predomina nos funcionários Satisfeitos | Improdutivos;
- Dentre os deligados, há um baixo percentual de salarios altos para funcionários Satisfeitos | Produtivos e Insatisfeito | Produtivo.
A empresa paga corretamente aqueles que mais produzem?
Esta visualização abaixo é meio redundante, pois já falamos sobre este ponto, porém deixo aqui mais uma opção para análise:

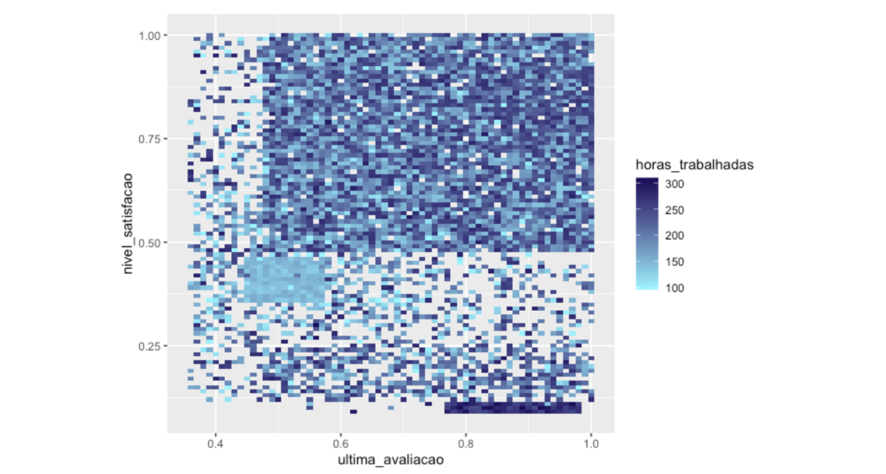
Verificamos aqui o que falamos anteriormente: que os funcionários de alta performance apresentam carga horária elevada de trabalho, enquanto que existe também uma concentração de poucas horas trabalhadas naqueles que consideramos Improdutivos | Insatisfeitos, o que pode indicar erro de contratação.
Para quem chegou até aqui, peço pra não me xingar (rsrsrs), mas eu acredito muito que o processo que seguimos enriquece todo nosso poder de análise. Porém, todavia, no entanto, alguns gráficos anteriormente utilizados se resumem neste em seguida, que, particularmente, gosto demais!

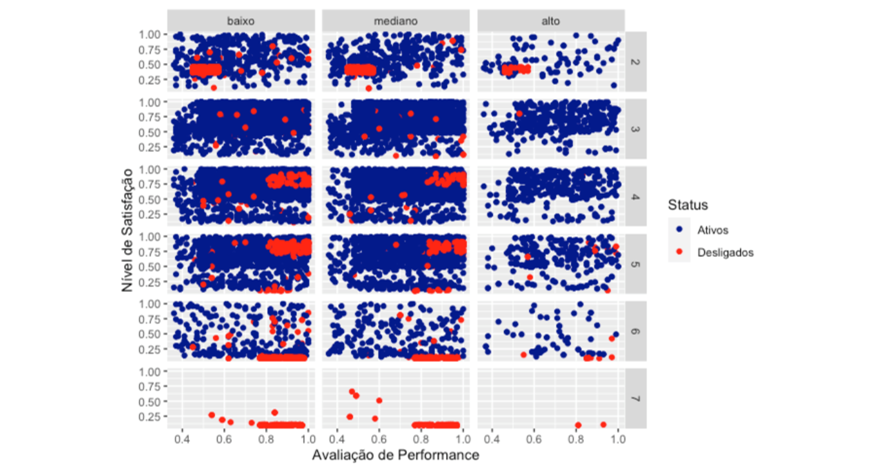
Neste gráfico de facetamento conseguimos cruzar cinco variáveis (quase que uma análise multivariada rsrsrsrs)! E nos traz muita informação. A dica também é aplicar o `ggplotly`, do pacote `plotly`, em que fica tudo dinâmico e podemos aplicar os zooms e analisar melhor cada face. Como já fiz análises mais detalhadas anteriormente, não o usarei.
Então, com este gráfico podemos verificar grande parte do que já vimos:
- Carga horária de trabalho elevada para aqueles que foram desligados e tem alta performance e baixa satisfação;
- Salários entre médios e baixos para aqueles que foram desligados e possuem alta performance e satisfação;
- Baixo número de projetos para aqueles que possuem baixa performance e baixa satisfação.
E aqui encerramos a nossa análise exploratória, que, convenhamos, nos traz muita informação e nos fará ter mais segurança sobre os resultados da nossa modelagem. Além disso, pudemos perceber que ficaram algumas perguntas no ar. Ainda vamos respondê-las na nossa conclusão. E sim! Agora vamos para modelagem!
Modelagem
Para a modelagem eu utilizarei o pacote `tidymodels`, que contém muitos outros pacotes e funções apropriadas para Machine Learning e facilita muito para quem lida com modelos diariamente!
Sem mais delongas, vamos ao modelo:
Primeiro passo é separar a base de treino e teste e fazer o pré-processamento da nossa base de dados. Isso envolve coisas como: tratar missings, excluir variáveis inúteis ou constantes, dentre outras milhares utilidades da função com prefixo `step`:


Agora que já tratamos nossa base de dados, vamos preparar nosso modelo, a reamostragem (validação cruzada) e colocar tudo em um objeto chamado wokflow, que agrega todos os elementos da nossa modelagem:

Com tudo pronto, agora vamos tunar os hiperparâmetros do nosso modelo, a fim de encontrar a melhor combinação para o tal de acordo com a métrica selecionada. Neste caso escolhemos `roc_auc`:

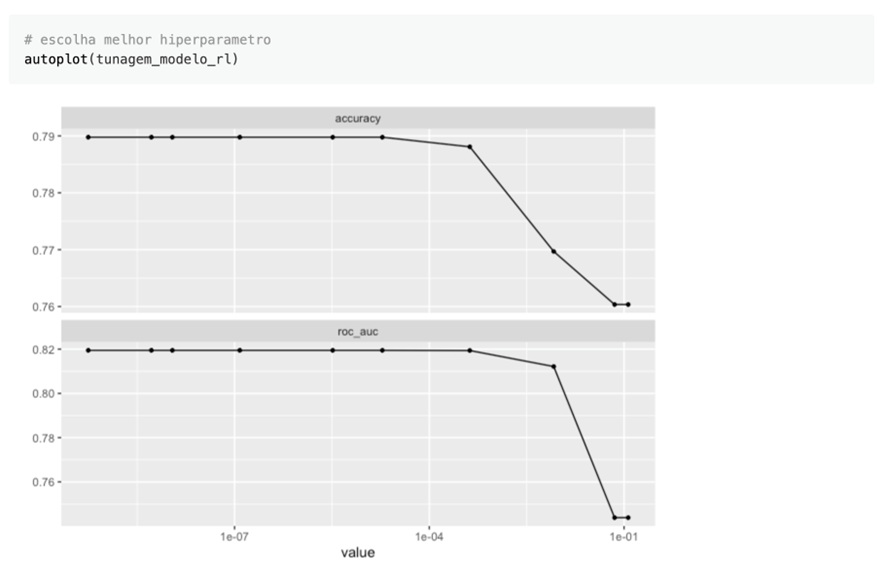

Modelo tunado, workflow atualizado, agora vamos testar nosso modelo e verificar as métricas dele:

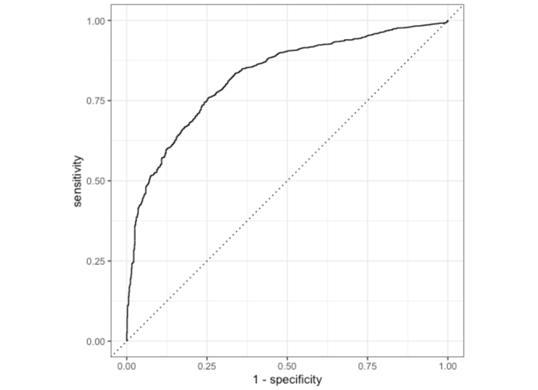
Vimos que nossa roc_auc está em 82% e acurácia de 79%. Bom patamar. Talvez um XGBoost consiga mais poder de predição, porém, um dos fatores de escolher a regressão logística é ela nos retornar, além dos coeficientes de importância das variáveis, a relação das mesmas com a variável resposta. Com isso, podemos gerar o seguinte gráfico:
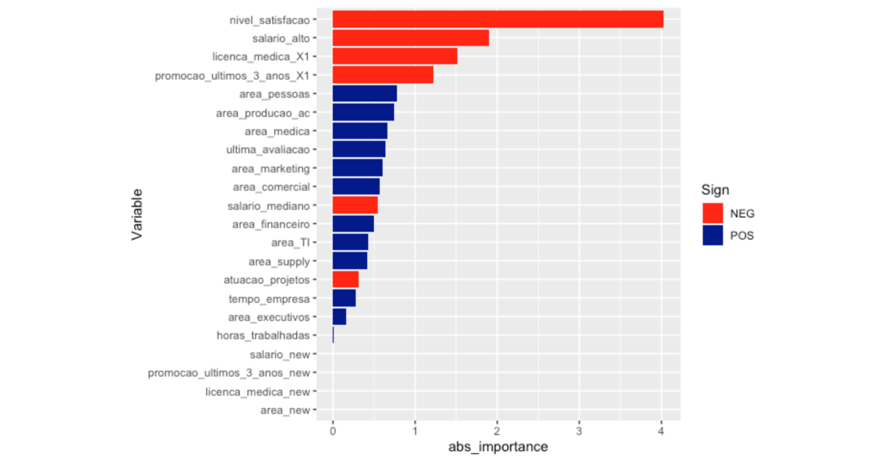
Podemos verificar que, de acordo com nossa análise exploratória, boas variáveis para classificar os indivíduos desligados são o nível de satisfação, salário, promoção e última avaliação. Além disso, o modelo nos traz a informação de que as áreas de trabalhos são boas preditoras juntamente com o a variável licença médica.
Tudo avaliado, agora podemos salvar nosso modelo para usar posteriormente:

Conclusão
Com todas as análises feitas, nós podemos recomendar e direcionar alguns pontos para esta empresa
- Controle de cargas horárias e atuações em projetos, pois bons profissionais estão sendo sobrecarregados;
- Reconhecimento salarial para aqueles que cumprem suas metas, pois existem funcionários menos produtivos que ganham mais do que aqueles produtivos;
- Melhorar a qualidade do recrutamento ou de contratação a fim de minimizar o desalinhamento dos profissionais e deixá-los insatisfeitos e improdutivos;
- Avaliar as áreas de pessoas e produção_ac, que representam grande chance de desligamento;
- Verificar se os direitos à licença médica estão sendo devidamente cumpridos, pois os funcionários que não exerceram esse direito tem mais chance de saída.
No mais, a empresa deve também dar mais atenção à satisfação de seus colaboradores e rever o processo de avalição de performance para verificar se este está sendo devidamente coerente.
Comentários
Esta foi uma pequena amostra de uma abordagem de Análise Exploratória e Machine Leaning para um problema de People Analytics. A base trabalhada é fictícia e está no portal Kaggle, só não lembro exatamente onde rsrsrsrs. Espero que possa contribuir com alguém e qualquer dúvida ou feedbak, só entrar em contato!
Agradeço a este Canal pela oportunidade de contribuir com o mundo de People Analytics!
Valeu!! 🙂

Rodrigo Almeida
Bacharel em Estatística, MBA em Machine Learning, Cientista de dados em experiência em diversos setores, explora oportunidades no assunto de People Analytics. Usuário do R e apaixonado por aprender e transmitir conhecimento!
IN: Rodrigo Almeida